Configure your data model
An integration's data model defines the properties and relationships of the data ingested from the integrated tool. It allows you to specify:
- How your data is represented in Port.
- The relationships between the integration and other data models in your catalog.
- The properties of the data ingested from the integrated tool and their types.
Your data model is defined using blueprints, which represent assets in your organization, and relations, which allow you to create logical connections between your blueprints.
Each blueprint is made up of properties, which are customizable data fields used to save and display information from your data source.
How to configure your data model
After installing an integration, you can configure its data model in the builder page of your portal.
To understand how an integration's data model works, let's take a look at an example.
After you complete the onboarding and connect your Git provider to Port, you will see a service blueprint that represents a microservice in your organization (which correlates to a Git repository):
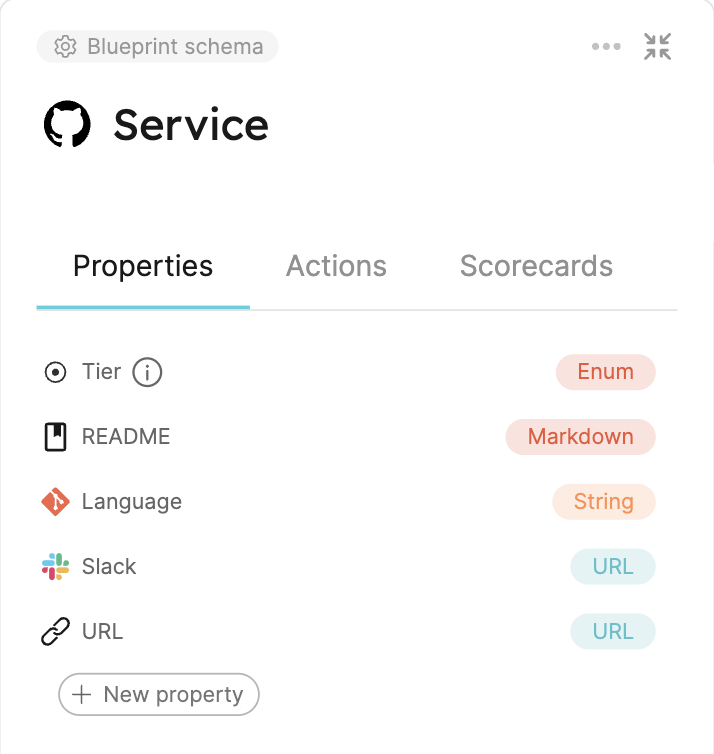
As you can see, this blueprint has several defined properties of different types. All entities based on this blueprint will have these properties filled with the ingested data from the Git provider.
Port's plug & play integrations come with predefined blueprints and their properties, but you can change anything you would like to fit your exact needs:
Configure properties
You can create, delete, or edit any property in any blueprint. This can be done from the builder page or directly from the software catalog.
After changing one or more properties, you may need to adjust the mapping of your integration to match the changes made to the data model.
Relate blueprints
After installing several integrations, you may want to relate blueprints of different integrations to each other, in order to create logical connections between them.
For example, say we have a Github integration and a Jira integration installed. We might want to relate Github's service blueprint to Jira's Issue blueprint. That way, we can easily see in our catalog which issue belongs to which service.